How Stickler CI grew from a prototype into a product
In this three part series, I’m going to cover the evolution of Stickler CI in the past 2 years from the initial prototype to the present day. This specific article will cover how I brought Stickler CI from an unprofitable project to a revenue generating product and the growing pains surrounding that journey.
Stickler CI is a software as a service application that automates a tedious part of code review; enforcing style and checking lint errors. It integrates with GitHub and checks each pull request for code style errors. Stickler CI will leave review comments when someone on your team makes a style error. This saves you time, as feedback on style errors is handled automatically, and your team doesn’t have to read through build reports to find whitespace errors. Our business model provides access on public repositories for free, while private repositories require a paid plan.
Real Customers, Real Problems
In January of 2017 Stickler CI attracted its first paying customer. The technical challenges mounted as the year progressed and we started to acquire more customers. Some of our misadventures included problems around cancellations, security, scaling up review jobs and handling the increased demand.
Incomplete Cancellations
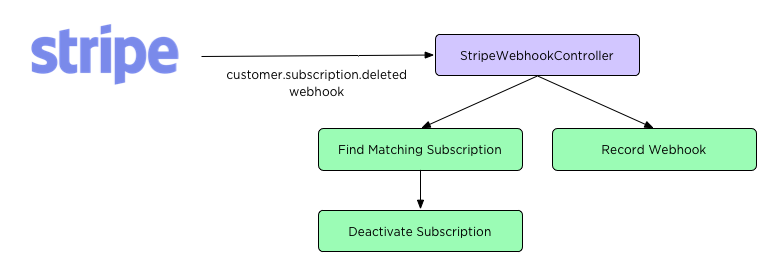
In the first implementation, we didn’t build workflows to handle cancellations. We had assumed that with so few paying customers churn would not occur for some time. To our surprise, a customer upgraded and needed to cancel much faster than we had anticipated. This resulted in a manual cancellation via email, and the implementation of a proper cancellation workflow afterwards. In addition to voluntary cancellations, a well rounded billing integration needs to handle a cancellations due to non-payment. In our haste to get paid plans shipped, we also neglected to build this functionality. This resulted in a few former customers having access to private repositories after their subscription was cancelled. To correct this oversight, we implemented the customer.subscription.deleted and invoice.payment_failed webhooks that Stripe sends when a subscription misses a payment or is cancelled for missing payments. Today when those webhooks arrive, the subscription is cancelled in our local database, preventing future reviews on private repositories.
Safety Second
Another issue with the initial offering was that we support linters that allow users to use linting rules they create with their own code. The ability to create custom rules allows users run whatever code they want on the Stickler CI servers. This presents a big security issue as malicious users could craft custom code to obtain API credentials or other private information. To remedy this gap, review jobs and linter execution was moved into a docker container, that has no access to the host filesystem containing secrets. After startup, the worker job drops privileges becoming an unprivileged user before running linters. Dropping privileges prevents custom linter code from accessing the environment variables the container was created with.
Keeping workers available
We cut a number of corners in how review jobs operated in order to release Stickler CI to market quickly. Some linters, like phpcs and eslint, support lint rules being defined in our user’s application code. These linters expose us to the risk that a nefarious user could put an infinite loop in one of their custom linter rules. An infinite loop would result in a locked review job worker, stalling reviews for all other users. This risk was mitigated by terminating review jobs that run longer than 10 minutes. We no longer have to worry about unpleasant users hogging our servers, with infinite loops, requiring us to provision more workers and impact Stickler CI’s profitability.
Memory is a fickle thing
As you may recall from the previous article, Stickler CI was originally deployed onto a single server. We didn’t anticipate how short lived that period would be.
Originally, the web-server had 1GB of RAM but soon became overloaded as review job traffic picked up. In response, that machine was upgraded to 2GB, but shortly after moving review jobs to docker, we started seeing various processes being terminated by my nemesis the OOMKiller (Out of Memory Killer). The system logs contained a number of ‘Killed process’ log messages. This told us that it was time to add more capacity, as our production environment was becoming over-capacity.
We quickly spun up a ‘worker’ machine by hacking together an Ansible playbook and some manual configuration. This configuration let us move docker and the review job processing to the new machine, freeing up precious RAM on the primary server. We also added small swap drives to both the worker and web-server hosts. This let us handle traffic spikes a bit and keep OOMKiller at bay. The resulting architecture of this change looks like:
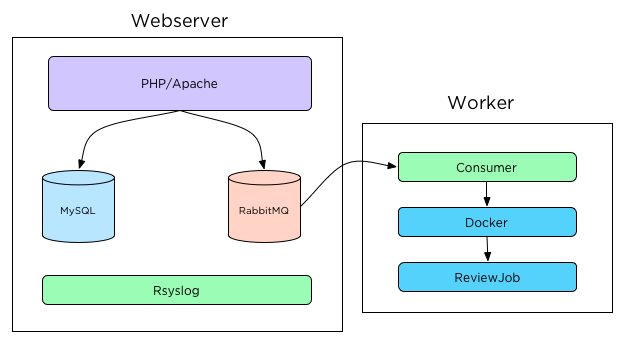
This configuration lets the worker node connect to RabbitMQ on the web-server, but run review jobs on its own docker daemon. Logs from the worker are forwarded to the web-server enabling us to have centralized logging, which makes troubleshooting easier. By running docker and review jobs on the worker we can better manage and isolate the resources (time & memory) that review jobs use and protect our web-server and database from expensive review job workloads. The docker container handles publishing review comments to GitHub, and allows us to re-queue jobs that fail with ease.
Conclusion
The end result of correcting these shortcuts was a more profitable, high performing, secure product. Stickler CI experienced the business impact of being able to take on more users, more reviews, and more revenue. The next article will investigate the fallout of our hastily built worker node solution and the nightmare of self-hosted email.
There are no comments, be the first!